Les empreintes numériques analysées

par Nicolas Sacchetti
Les empreintes numériques ont un potentiel pour analyser et révéler les tendances comportementales, économiques, industrielles et sociales. Ce sont des sources de données non traditionnelles.
Au début des années 2000, le concept des mégadonnées a commencé à émerger en tant qu’ensemble de données importantes qui nécessitent des méthodes d’analyse avancées pour être exploitées. Vingt ans plus tard, les mégadonnées transforment la politique socio-économique et la recherche afin de servir la gestion des entreprises et la prise de décision.
Joseph Domenech est un professeur agrégé au département d’Économie et de Sciences sociales à l’Université Polytechnique de Valence. En tant que chercheur, il s’intéresse entre autres aux approches multidisciplinaires des systèmes internet et à l’économie numérique.
Professeur Domenech a présenté une visioconférence sur les sources de données non traditionnelles utilisées pour la recherche économique dans le cadre du premier Congrès 2021 4POINT0 sur les politiques, les pratiques et les processus liés à la performance de l’écosystème de l’innovation 2021 (P4IE).
Les technologies de l’information et de la communication (TIC) sont présentes dans la plupart des activités quotidiennes. Les entreprises peuvent notamment lancer des campagnes publicitaires en ligne, géolocaliser les cellulaires des représentants aux ventes, ou encore mettre des capteurs dans les lieux de travail et sur les machines.
Pour les individus, les TIC servent souvent à faire des achats en ligne, émettre des opinions, ou suivre des indications GPS. Toutes ces activités laissent des empreintes numériques. « Lorsque nous mesurons les activités en ligne, nous devons considérer le comportement numérique des compagnies et des individus, » explique Domenech.
Classification d’empreintes numériques
La classification des sources de données peut être faite selon l’intention des utilisateurs. Il y a des sources qui sont reliées à la diffusion d’information sur des sites internet ou des pages Wikipédia. D’autres sont reliées aux interactions des plateformes de partage d’opinions. Certains, sur les transactions web, ou des sources de données que les utilisateurs ont générées à leur insu, c’est-à-dire que ceux-ci peuvent ne pas être pleinement conscients de la collecte de ces données et de l’utilisation qui en est faite. Il s’agit notamment des témoins de navigation (cookies), les adresses IP, les coordonnés GPS des appels téléphoniques (CDR – Call Detail Records), ou encore les données des accès wifi utilisés.
Méthodes pour structurer les données
Comme la plupart des mégadonnées ne sont pas structurées, un processus de transformation des données en un ensemble organisé est nécessaire. Domenech présente deux méthodes de classification. Soit la structure de données (Data Structuring) et le modèle relationnel (Modeling Relations).
Structure de données
La stucture de données est une manière de les disposer dans une base de données et d’organiser les liens qui permettront de les retrouver.
Modèle relationnel
Le modèle rationnel est un « modèle dans lequel les données sont disposées dans une table pour laquelle des relations sont établies entre certaines lignes et colonnes. Il est très populaire car il permet d’économiser de la mémoire en évitant de copier les mêmes données dans des fichiers différents (redondance). Il permet en outre de préserver la cohérence des données qui n’ont besoin d’être mises à jour que dans un seul fichier. »
Traitement automatique du langage
Le traitement automatique du langage (TAL) (Natural Language Processing – NLP) est un domaine de recherche englobant de nombreuses techniques visant à faire comprendre aux ordinateurs des textes écrits par des humains. Les techniques incluses dans ce procédé sont davantage développées en anglais que dans toute autre langue.
Quelques techniques comprises dans le TAL
Sac de mots
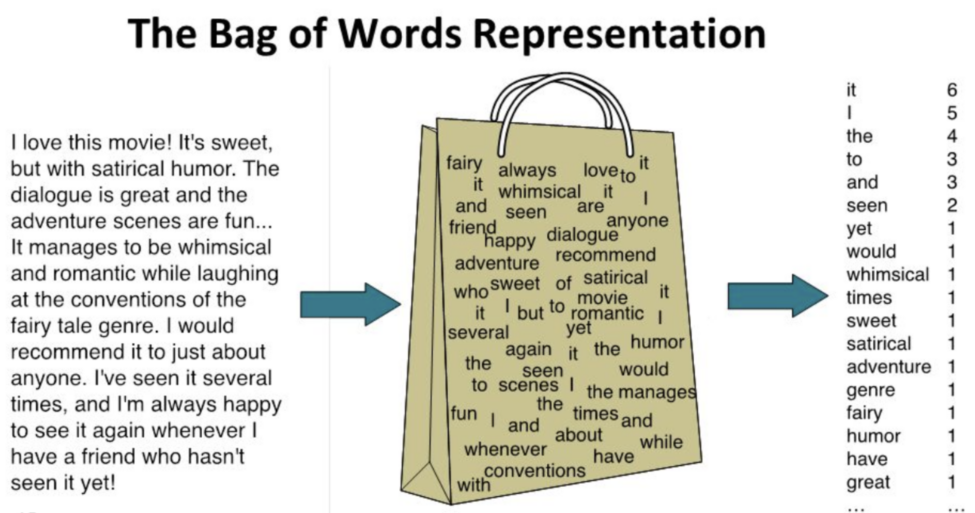
Le modèle du sac de mots (Bag of Words Model) fait une représentation d’un texte en comptant le nombre de fois que chaque mot apparaît.
TF-IDF
Le TF-IDF (Term Frequency-Inverse Document Frequency) est une « mesure statistique qui permet d’évaluer l’importance d’un terme contenu dans un document ».
Normalisation textuelle

La recherche de radical (Stemming) et la lemmatisation (Lemmatization) sont des opérations en traitement automatique du langage naturel qui visent à réduire les mots à leur forme canonique, c’est-à-dire leur forme de base.
Cette forme canonique permet de représenter tous les mots qui partagent la même racine ou le même lemme. Cela permet de normaliser le texte et de faciliter la comparaison entre les différents documents ou corpus textuels. La recherche de radical consiste à enlever les suffixes et les préfixes d’un mot pour ne garder que sa racine, tandis que la lemmatisation vise à trouver le lemme, c’est-à-dire la forme canonique d’un mot qui peut être utilisée pour représenter toutes ses variantes flexionnelles.
Analyse de sentiments
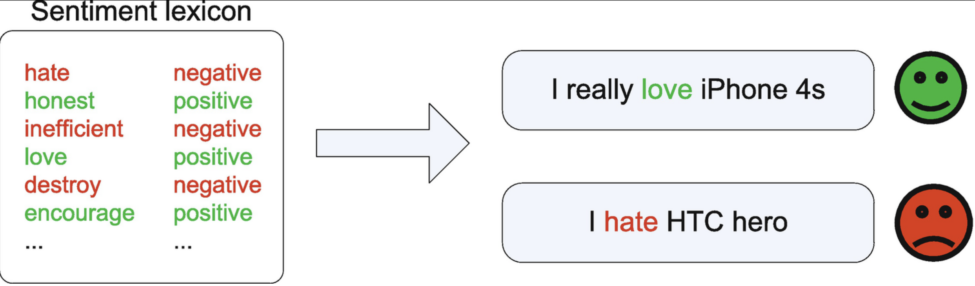
L’analyse de sentiments (Sentiment Analysis/Opinion Mining) est une technique d’exploration de texte qui sert à déterminer le sentiment des internautes relativement à différents aspects d’un produit, d’un établissement, d’un film ou d’un parti politique.
Analyse sémantique latente
L’analyse sémantique latente (Latente Semantic Analysis) tente de déterminer le sens d’une phrase à partir d’un ensemble de règles.

Allocation de Dirichlet
L’allocation de Dirichlet (Latente Dirichlet Allocation) « est l’une des méthodes les plus populaires pour effectuer la modélisation des sujets. Chaque document est composé de plusieurs mots et chaque sujet peut être associé à certains mots. L’objectif est de trouver les thèmes auxquels le document appartient, sur la base des mots qu’il contient. »
Harmonisation des données
L’harmonisation des données (Data Match) est une technique qui permet de relier les informations d’un même utilisateur (ou d’une même entité) à travers différentes sources de données. Un cas particulier est la déduplication, c.-à-d. d’éliminer les données redondantes dans un système de sauvegarde.
Méthode de modélisations
Il y a deux modèles de pensée en ce qui a trait à la modélisation. Pour l’apprentissage supervisé (Supervised Learning), chaque observation dans l’ensemble de données a des entrées (inputs) et des sorties (outputs). Les entrées sont équivalentes aux variables indépendantes, aux caractéristiques, ou aux prédicteurs. Les sorties sont équivalentes aux variables dépendantes, aux cibles, ou aux réponses.
Pour l’apprentissage non supervisé (Unsupervised Learning), chaque observation a des entrées, mais pas de sorties. L’objectif est de trouver les relations ou la structure entre les entrées.
Il existe d’autres techniques que l’on peut combiner pour améliorer les performances des méthodes précédentes, notamment les algorithmes d’apprentissage ensembliste (Ensemble Algorithms), tels que le Bootstrap Aggregating (Bagging), et les forêts aléatoires (Random Forest). Les méthodes de régularisation, telles que le LASSO, le filet élastique (Elastic Net), et la régression pseudo-orthogonale (Ridge Regression). Et les méthodes bayésiennes, telles que le Model Averaging, le Bayesian Structural Time Series (BSTS), la régression Spike-and-Slab.
Méthodes d’évaluation
L’objectif de l’évaluation est d’obtenir un modèle robuste avec la meilleure performance de prédiction hors échantillon. La performance fait référence à la façon dont le modèle s’adapte aux données d’entraînement, tandis que la robustesse se réfère à la façon dont le modèle fonctionne avec des données inédites. Cependant, les tests traditionnels tels que R2, AIC, BIC, et logarithme du rapport de vraisemblance (Log Likelihood Ratio) ne sont pas toujours adaptés pour traiter de grandes quantités de données complexes (Varian 2014).
Un processus d’attente peut aider à garantir la robustesse du modèle. Pour ce faire, l’échantillon initial est divisé en trois parties : l’ensemble d’entraînement, l’ensemble de validation et l’ensemble de tests. Les approches courantes pour la validation croisée sont la validation croisée K-fold et la validation croisée avec exclusion.
Lecteurs optiques
Domenech a de l’intérêt pour le projet de Eurostat du Guide des statistiques dans la coopération au développement de la Commission européenne. Le projet consiste à utiliser les données des lecteurs optiques aux caisses des commerces de toutes sortes telles que les supermarchés et des détails afin de mesurer l’indice des prix à la consommation. Cette source de données témoigne aussi de l’intérêt aux nouveaux produits, et détecte les boycottages des consommateurs.
L’introduction de la technologie des scanneurs de codes-barres dans les années 1970 et son développement au cours des XXe et XXIe siècles ont permis aux détaillants de saisir des informations détaillées sur les transactions aux points de vente. Les données des scanneurs sont volumineuses et contiennent des informations sur les transactions individuelles, les dates, les quantités et les valeurs des produits vendus, ainsi que les descriptions des produits. En tant que telles, elles constituent une riche source de données pour les services nationaux de statistique (SNS) et sont de plus en plus fréquemment utilisées pour le calcul des indices des prix à la consommation (IPC). Les données des scanneurs sont recueillies soit directement par les SNS grâce à des accords avec les détaillants, soit indirectement auprès d’intermédiaires, ou de sociétés d’études de marché.
– Eurostat 2021, Guide to statistics in European Commission development cooperation, p.49
Site web
Le site internet d’une compagnie est relié à son image publique. Il informe entre autres à propos de ses produits et services, sa structure et ses intentions. Sa fonction est d’informer, de faire des transactions, et de faciliter le partage d’opinions. Domenech explique que toutes ces informations servent à analyser les comportements d’une compagnie.
Analyse
L’analyse comportementale des internautes qui naviguent sur un site se fait par la considération des visiteurs uniques (Page views) sur les différentes pages. Le web analytics permet aussi cette étude.
En ce qui a trait à l’analyse du contenu des pages, une stratégie consiste à définir des mots-clés et à compter le nombre de fois qu’ils reviennent sur la page. « Par exemple, si nous souhaitons savoir combien de compagnies travaillent sur technologie particulière, nous pouvons définir ce mot-clé et essayer de le trouver sur leur site internet. C’est une mesure quantitative sur l’intensité que cette technologie a dans les différentes compagnies », précise Domenech.
D’autres approches sont possibles quant à l’analyse du contenu des pages web. Le TAL permet de savoir les langues traduites disponibles, les sujets traités, et de déterminer si les échanges sont courtois et positifs entre les individus sur ces pages internet.
À un autre niveau d’analyse, le code HTML décrit le contenu de la page. Il donne des informations sur la technologie utilisée pour la coder. Un site web ayant des fonctionnalités dépréciées est interprété comme appartenant à une compagnie dont la valeur économique est en déclin.
Le site-level analysis analyse le site en tant qu’entité. « Nous analysons la structure des liens du site comme une analyse de réseau. Nous pouvons voir comment le site est relié à d’autres acteurs de l’écosystème de l’innovation », dit Domenech.
Aussi, afin de voir l’évolution dans le temps et d’apprécier l’innovation réalisée par une compagnie, la Wayback Machine permet de visualiser les versions antérieures des sites internet.
Réseaux sociaux
Les informations qu’ils contiennent sont, dans une certaine mesure, le reflet de ce qui se passe dans la société. Le site le plus populaire de service de microblogue est Twitter. Les données de Twitter sont utilisées pour effectuer des recherches en économie et en sciences sociales. Que ce soit pour décrire les préférences politiques et prévoir les résultats des élections, prédire les mouvements du marché boursier, prévoir les entrées dans l’industrie cinématographique, ou pour surveiller l’opinion publique sur de nouvelles politiques. L’orientation des réseaux sociaux vers un segment de la population nécessite d’utiliser certaines mesures statistiques de correction lors de ces prédictions.
Bien sûr, les compagnies utilisent les réseaux sociaux pour annoncer de nouveaux produits et services. L’innovation dans les produits peut être reflétée dans ce qui y est présenté, ainsi que l’interaction entre différents acteurs de l’écosystème d’innovation peut y être analysée.
Moteurs de recherches et Google Trends
Google Trends permet de mesurer l’intérêt des gens pour les nouveaux produits ou services en temps réel (échantillon aléatoire des sept derniers jours), ou en temps différé (échantillon aléatoire du jeu de données (dataset) depuis 2004 jusqu’aux 36 dernières heures. Google Trends fournit un indice de volume de recherche (Search Volume Index – SVI). Ce qui permet de connaître les tendances de la popularité des sujets, mais il est difficile de comparer des pays ou des régions dues à l’absence de données absolues (module – maths).
Josep Domenech termine sur ces mots : « Les données numériques offrent de nombreuses possibilités, mais posent aussi de nombreux défis. Nous devons changer les systèmes de gestion des données, et nous devons apprendre de nouvelles méthodes d’analyse, car les données numériques ont changé les façons de faire traditionnelles. Ces nouvelles approches nécessitent un point de vue multidisciplinaire. Nous avons besoin d’équipes de professionels·les qui gèrent les données, qui ont le savoir sur les sources, et qui savent les interpréter. »
Ce contenu a été mis à jour le 2023-03-14 à 18 h 08 min.